
GPT-4就是冲着赚钱来的?
在惊艳到出圈的ChatGPT推出后仅仅4个月,OpenAI再推新品。这似乎正在印证此前传出的“OpenAI计划2023年营收2亿美元,2024年底前营收达10亿美元”的目标。限制盈利机构OpenAI要开始用大模型赚钱了。
目前官宣的GPT-4能力与此前传说的基本相似,主要提升了语言模型方面的能力,并添加了“多模态”的图片识别功能。此外,GPT-4 将“单词最大输出限制”提高到了 25000 个单词,比基于GPT-3的ChatGPT更强大,在对问题的理解和回答方面,GPT-4也显得更聪明,更像人了。目前,ChatGPT Plus版本的用户已经可以直接在原来的ChatGPT基础之上,选择GPT-4模型,直接体验。不过,目前GPT-4每4小时只能回答100个问题。
在前不久的GPT-4“谣言”阶段,微软就曾多次通过各种渠道透出New Bing会第一时间应用GPT-4。新模型发布后,微软更是在第一时间宣布“我们很高兴确认新的Bing正在运行GPT-4,我们已经为搜索进行了定制。如果您在过去五周中的任何时候使用了新的Bing预览版,那么您已经体验到了这个强大模型的早期版本。”
在参数量方面,在OpenAI公布的GPT-4论文中,并没有之前一直传说的“100万亿参数”,甚至没有提及GPT-4到底用了多少参数,不过笔者亲测ChatGPT Plus中开放的GPT-4功能后感觉,回答的速度比GPT-3.5要慢了一些。
“单从回答速度比ChatGPT慢来说,并不能表明GPT-4的参数量就更大。”大算力AI芯片存算一体专家,千芯科技董事长陈巍博士认为,OpenAI不公布参数量和架构是一种商业化技术保护策略,增加其竞争对手的产品试错成本。不过目前也没法排除GPT-4参数量小于GPT-3的可能性。
迅速落地商业应用,保密参数量,增加图片识别能力,大幅提升语言模型能力。GPT-4的推进速度,比4个月前的ChatGPT快了不是一步两步。
商业化能力再提升,GPT-4能去赚钱了?

“GPT-4已经突破了落地的问题,采用云的方式,用的人越多,成本越低。”云舟集成电路创始人兼CEO赵豪杰认为,GPT-3会更偏向NLP,而GPT-4在各方面的能力都更强一些。他给虎嗅举了这样一个例子,GPT-3就像初中生,还不能出来工作赚钱,GPT-4应该已经职校毕业,可以上班赚钱了。
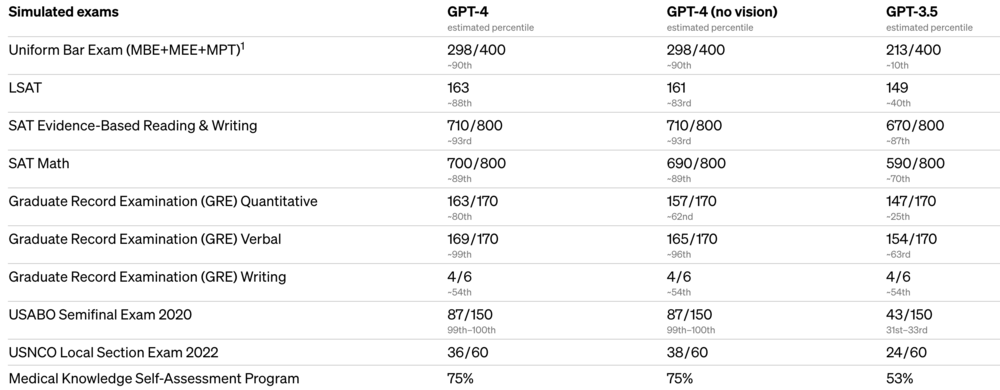
GPT-4的能力虽然在很多现实场景中不如人类,但在各种专业和学术基准测试中表现出了与人类相当的水平。不管怎么说,GPT-4确实在商业化上更进一步了。
在此之前,ChatGPT以及GPT-3在专业领域的表现一直被人们认为差强人意,在美国的律师资格考试Uniform Bar Exam (MBE+MEE+MPT)中,GPT-4的成绩甚至可以排到前10%,而GPT-3.5只能排在倒数10%。GPT-4在专业领域的能力实现了巨大提升,在一些专业领域已经开始逐渐接近甚至超过人类,这给GPT-4在很多ToB商业领域提供了更多可能性。
例如,专业技能辅助工具,知识检索类的应用,职业教培辅导等领域,GPT-4的能力将是革命性的。对于GPT-4在专业技能上的突破,如果再进一步思考,或许未来人类的职业技能,将被AI重构。而在教育和技能培训方面,或许现在就该开始思考,哪些技能AI无法取代,我们应该学习什么知识和技能,以保持身为“人类”的不可替代性。
相比于GPT-3和GPT-3.5,GPT-4的智力更强,更不易出错,这显然有利于商业落地,而新增的图片识别功能则给OpenAI找到了更多的应用场景。
GPT-4能够基于视觉信息做逻辑推理,不仅告诉用户眼前发生了什么,更能说出发生的事代表了什么。目前,OpenAI已经给GPT-4找到了一个社会价值非常高的应用场景——助残。
BeMyEyes 是一家总部位于丹麦的公司,他们致力于在日常生活中帮助视障人群。BeMyEyes的基础功能是在App中招募,通过链接志愿者和视障人士,为他们提供“视力”帮助。
OpenAI 此次公布GPT-4时,也公布了他们和BeMyEyes的密切合作,通过GPT-4的多模态识别功能,为视障人士提供更便捷的“虚拟志愿者”(Be My Eyes Virtual Volunteer™)。用户可以通过该应用程序将图像发送给给予GPT-4的“虚拟志愿者”, AI将为各种任务提供即时识别、解释和对话式的“视力”帮助。
目前该功能正处于封闭测试阶段,预计将在接下来的几周内扩大 Beta 测试人员群体,并有希望在未来几个月内广泛提供虚拟志愿者。该应用在中国App Store亦可下载中文版本,目前也已经开放了公测排队。Be My Eyes声称“该工具将对所有使用 Be My Eyes 应用程序的盲人和低视力社区成员免费。”
“真正的多模态大模型还没有来,期待GPT-4.5和GPT-5,还会在多模态上有很大进展。”源码资本执行董事陈润泽告诉虎嗅,多模态大模型还有很大发展空间,未来也会带来更多的应用场景。
虽然GPT-4大幅拓宽了大模型可能落地的商业化场景。但算力、研发成本,仍被很多人认为是大模型落地过程中很难跨过的障碍。毕竟大模型的研发、算力支出在目前看来高的吓人,此前ChatGPT公开的单次训练、日常运营开支都是以百万美元为单位的,短期内想要商用可能很难控制成本。
不过,陈巍认为,在商业化方面GPT-4更容易落地。成本是否更高要看多方面因素,GPT-4总的固定研发成本(含预训练模型的训练成本,不是增量成本)高于ChatGPT,但可以看到OpenAI已将GPT-4开放在ChatGPT Plus生产环境中,因此不排除GPT-4模型运行成本更低的可能。
在NLP研究领域,专家们一直在尝试不依赖大算力来进行LLM训练,但目前还没有特别好的解决方案。从仿生学上来看,人脑本身是不需要依赖非常大量算力进行学习的,因此随着脑科学技术研究的深入,未来应该会有一种技术替代现在的暴力训练方式。但是即便不考虑训练,大算力确实会给模型的部署应用带来更好的性能提升。
陈巍认为,存算一体(CIM)架构或类脑架构(并不特指SNN架构),或者两者的异构结合,这两类架构都更接近人脑的逻辑结构,可以有效的提升有效的训练算力,给AI训练和研发提供更高效的算力工具。(当然并不排斥这两者与现有CPU或GPU技术的异构整合)
事实上,OpenAI的大模型在成本方面正在以肉眼可见的速度下降。3月1日,ChatGPT刚刚公布开放API时,即已声明成本比最初降低了90%。目前,已公开的GPT-4的API价格则大概是纯文本输入每1k个prompt token定价0.03美元,每1k个completion token定价0.06美元。默认速率限制为每分钟40k个token和每分钟200个请求。对此,赵豪杰表示:“GPT-4已经突破了落地的问题,采用云的方式,用的人越多,成本越低。”
除了成本,利润也是非常关键的,陈润泽认为,OpenAI在GPT-4的论文中用了大量篇幅讲述他们在安全可控方面的努力。“GPT-4(launch)做了更好的安全约束。技术的进步是多要素综合,利润也会与之一起驱动商业化落地。”
“中国的OpenAI”们路在何方?
“各家模型之间没有明显可比性,他们的区别主要在于投入市场的节奏,以及用户数量。”伍尔德里奇教授认为,OpenAI的大模型从技术上来讲,优势并没有那么夸张。相对于其他产品来说,只是问世更早而已。然而,正是因为比其他产品更早投入市场,也意味着它比其他人获得了更多的用户,以及反馈数据。
GPT-4发布之后,OpenAI在产品上又领先了全球一步。在国内追赶ChatGPT的队伍中,百度的文心一言或许是最接近的,目前已经官宣了今日(3月16日)发布,然而GPT-4又比百度早发一天,从这方面上看,重压之下,国内厂商追赶OpenAI看起来也越发困难了。
不过,对于中国的大型语言模型市场,多数专家认为,中文实际上是“原发”劣势。基于中文的模型与英文模型差别很大,中文互联网的复杂程度远高于英文,而且数据、信息量也更大,这使得语料收集、建模、训练,都要比英文困难很多。“中文本来就难,不过在中文大模型这方面,先不管好不好用,必须要有。”赵豪杰对虎嗅如是说。
“GPT-4和ChatGPT都是AI技术进步道路上的短暂风景。包括开源社区也在推进OpenAssitant等类ChatGPT开源模型。”陈巍表示,“我们提倡的思路是,产业界参考OpenAI的路线迅速追击,勤劳的同胞可在垂域上做出更好的细分领域模型;学术界则尝试更高效率的训练方法或更高性能的模型结构,尝试找到暴力训练之外的路径。”
目前看大模型和算力芯片已经成为AI产业发展的两个主驱动轮,两个都要持续投入和推进才能获得更好的产业地位和战略优势。
OpenAI在发布GPT-4的同时,还公布了一项有意思的开源。即用于评测大语言模型的OpenAI Evals框架,该框架可以通过数据集自动生成提示(Prompt),评估模型生成的回答/补全(completion)的质量,比较不同数据集或模型的性能。
“这类评测框架在各NLP企业中一直存在,但较少开放。”陈巍对虎嗅表示,OpenAI这一举措可能有助于NLP领域建立起统一的LLM评测标准,可能节约小企业建立评测体系和训练数据集的时间和成本。
不过,陈巍同时提示,有一点需要注意,就是在Evals的免责声明(Disclaimer)中,OpenAI 保留在其未来产品中使用这些Evals用户上传的数据的权利。
来源|虎嗅
作者|齐健 编辑|陈伊凡


